summary
- We can instruct language models to extract key pieces of information from a text as structured lists of data
- Structured lists can be viewed in different ways depending on the task or question
- Language models can help us compare two lists of information to see relationships between them
Concept Video
imagine if you could take the raw material of websites and shape it into new forms pic.twitter.com/bHTawf9YPZ
— Matthew Siu (@MatthewWSiu) September 21, 2022
Overview
One of my long term research interests is in how we shift the balance of time spent consuming vs. creating in digital spaces. To turn the computational medium into a digital workshop where we are gathering materials and shaping them into the form we need to communicate an idea or answer a question.
This concept video communicates some of the actions I imagine the computational medium could help us do. I also include some questions a person may have where these actions might be useful.
- Action: Take an article and extract specific entity types from the text. People, locations, concepts, links, images, bolded/italicized text.
- Who is mentioned in the text?
- What are some of the key ideas in the text?
- What should I read to learn more?
- Many ways to do this, two approaches: This could be just extracting links from the text. Or you could use the key ideas in the text to search for related content.
- Action: Elaborate on each element in a list by getting additional metadata information. Language models could synthesize or find the information we requested on demand.
- What is the history behind this entity (location, person, etc)?
- What is a short summary of the entity?
- What else is this entity related to? Who else?
Related literature
This video is inspired by work into end-user programming and data-driven design. When we see people’s workshops in the physical space, they vary quite a lot. Each person’s work and workflow looks unique. However, in the digital space, our interfaces and spaces are for the most part the same even though the types of work people do in digital spaces is just as varied.
Both end-user programming and data-driven design promise higher level customization and personalization in our digital workspaces. Also, multiple views on the same information depending on the question or task at hand.
Exploration
Since this concept video, I’ve started building some of the components necessary to perform these types of actions on arbitrary texts. To avoid the limitless edge cases of web scraping, I’ve focused on ingesting RSS feeds for now.
.png)
This is a basic interface for extracting datasets from the texts. In this case, I’ve selected three articles and am requesting all the “Person” entities from these texts

This is the extracted dataset. The title is generated using a language model that synthesizes the titles of the files selected. Elements can be sorted and deleted. You can get additional suggestions for elements to add to the list similar to Spotify suggestions. You can also request a description for each of these elements.
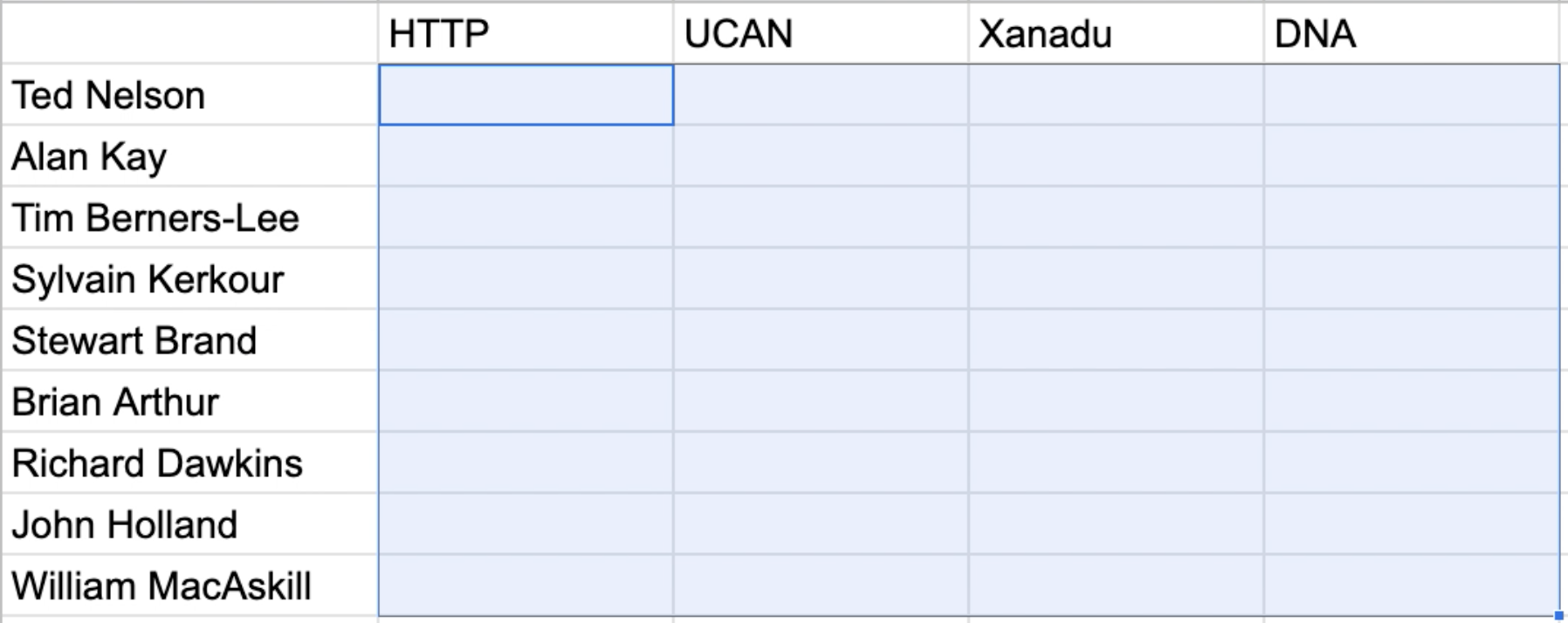
Another possible interface for manipulating lists of data could be more excel-like. You might have two lists and want to populate information about how each is related to each other.
Eventually, you could train a language model to control these functionalities and options from a natural language query given by an individual. Similar to what I’ve shown in the concept video.
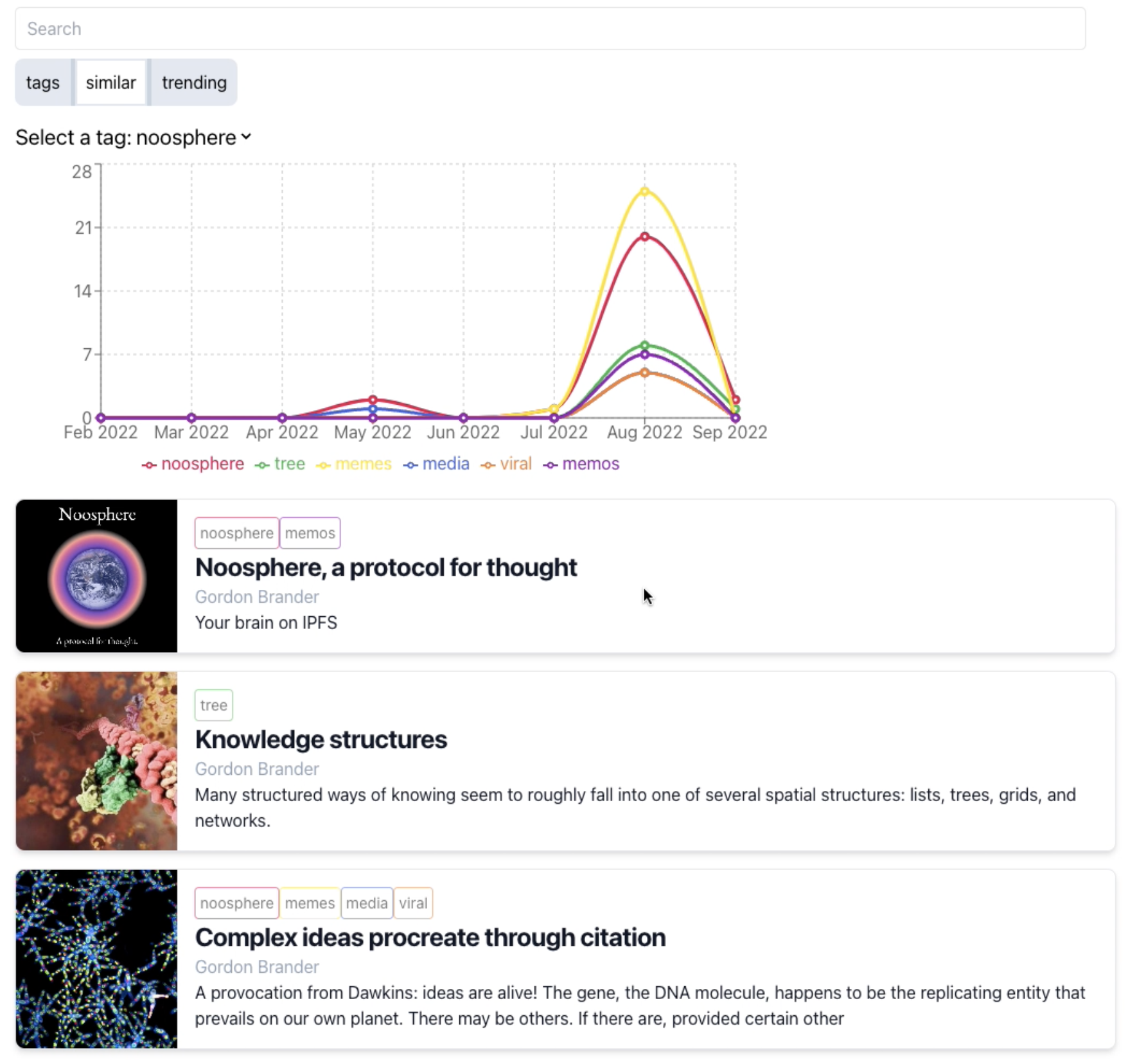
This interface explores one possible view on top of this extracted data. A google trends like interface on your own writing. You can see what terms are mentioned most together, see recent trends and also explore relationships between arbitrary concepts. The intent here is to better understand how the interests of a body of work change over time.